最近は、Shift_JIS(Windowsでいうならcp932)には2バイト目に「¥」(0x5C)が混じった文字がある事すら知らない人が居るようで...
すこしカルチャーショックを受けたオジサンmattnです。
職場でUNIXからWindowsに移植したソースコードでコンパイルが通らない!と悩んでいらっしゃる。
そしてその原因がオリジナルを書いた人のコードが悪いと...
まぁ確かにソースコード内に日本語書いてた人が悪いのかもしれませんが...
今日はみんな知ってそうな話。知らなかったら知っといてねくらいの話。
そんなに珍しい話じゃないんですよね。ソースコード内に埋め込みの日本語って。まぁ理由はポータビリティだったり、ソースコードを簡潔に書く為だったり、単純に面倒臭かっただけだったりと(爆)...
昔は結構あったんですよ。ソースコードがeuc-JPなソースとか。
ただそれは、昔は普通にあった話で開発者なら知っておきたい事かな。
まぁここでボヤいても、その担当者には伝わらないんだろうけど。
euc-JPとは違い、Shift_JISには後続するバイトとして0x5Cが来る事があります。
例えば、「ソ」「表」「噂」「貼」など。あと「―」(DASH)もそうですね。
ソースコードの中で罫線などを書く場合によく埋め込みでDASHが書かれたソースコードってのもありました。
で、これが何故問題になるか。もうわかりますね。
C言語等のソースコードでは「¥」(0x5C)はエスケープ文字のリーダとして働くからです。
コンパイラは通常、そのソースがeuc-JPなのかShift_JISなのかUTF-8なのか知りません。javac(gcj)等では「--encoding」なんてオプションで入力ソースのエンコーディングを指定出来たりもしますが、通常のCコンパイラではそうは行きません。
Microsoft Visual C++(日本語版)のコンパイラはShift_JIS(もしくはUnicode)を
特例として許しているだけです。
ソースコードは世界の誰がコンパイルしても同じモジュールを作ることが出来るべきであって、日本製のコンパイラでしかビルド出来ないソースってのは異端児もいいところかと。
まぁソースコードに生マルチバイト書くなんて...ってのが本筋ですが。
今日は、古き良き(?)時代のジョークプログラムをWindowsに移植する時の注意点を示してみます。
昔、UNIXで「ls」を「sl」とタイプミスした時に、端末上にSLが突っ走るジョークプログラムがありました。
私も気に入って入れたりもしました。
「sl」も気に入っていたのですが、改変版の「quit」がさらに好きでした。
さすがにshellをsqlplusなんかと間違う事は無かったので本気でshellに「quit」と打ち込むことは無かったですが、「もう来ねぇよ!」と端末を走るAAが気が和んで楽しかったです。
で、そのquitですが私が確認した所
福地さんののページにある
ショートショートプログラムの部屋
にバージョン1.2aとして置いてありました。
さっそくダウンロードし解凍。
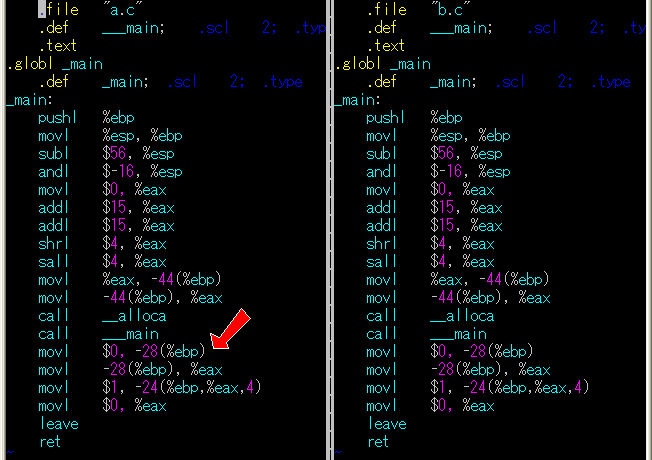
まずeuc-JPで書かれているソースをShift_JISに変換するのですが、ここで問題が起きます。
上でも述べた様に、Shift_JISには後続するバイトに「¥」(0x5C)を持つ物があるのですが、このquitのソースに記述されている「―」(DASH)は、Shift_JISで表すと「0x81 0x5C」というバイト列。つまりうかつに変換してしまうとC言語のエスケープ文字を自ら作ってしまう事になるのです。
案の定、以下の様にnkfで変換したソースはそのままコンパイルする事が出来ません。
C:¥temp¥quit-1.2a>nkf -g *
Makefile:ASCII (LF)
quit.1:EUC-JP (LF)
quit.c:EUC-JP (LF)
quit.h:EUC-JP (LF)
quit.txt:ASCII (LF)
README:EUC-JP (LF)
C:¥temp¥quit-1.2a>mkdir tmp
C:¥temp¥quit-1.2a>copy quit.c + quit.h tmp
quit.c
quit.h
1 個のファイルをコピーしました。
C:¥temp¥quit-1.2a>nkf -EsX quit.c > sjis_quit.c
C:¥temp¥quit-1.2a>nkf -EsX quit.h > sjis_quit.h
C:¥temp¥quit-1.2a>del quit.c quit.h
C:¥temp¥quit-1.2a>rename sjis_quit.* quit.*
C:¥temp¥quit-1.2a>mingw32-make CC=gcc CFLAGS="-O -DJAPANESE=1"
gcc -O -DJAPANESE=1 -o quit quit.c -lncurses
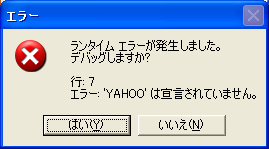
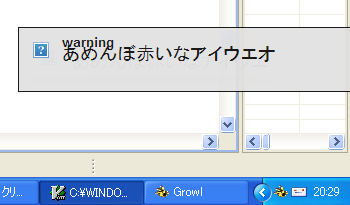
quit.c:47:49: warning: unknown escape sequence '¥|'
quit.c:47:49: warning: unknown escape sequence '¥|'
quit.c:47:49: warning: unknown escape sequence: '¥201'
quit.c:47:49: warning: unknown escape sequence '¥|'
quit.c:238: error: stray '¥26' in program
quit.c:238:2: warning: no newline at end of file
mingw32-make: *** [quit] Error 1
※ギコ猫版をビルドするには「-DJAPANESE=1」が必要です。
※コンパイルはMinGWで行っています。(pdcursesも必要)
で、これを修正するには「0x5C」が後続する文字の後に「¥」を付けてコンパイラがエスケープ開始文字と混同しないように教えてあげます。
例えば「―」(DASH)であれば「―¥」となります。
コンパイル結果から、一つずつ直していっても良いのですが、実はこれコンパイルエラーとなっていない場合もあります。
例えば「―t」という表示があった場合、コンパイラは変な1文字と「¥t」(タブ文字)があるかの様に振るいます。
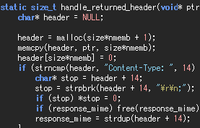
実際の例で言えば
#include <stdio.h>
#include <string.h>
int
main(int argc, char* argv[]) {
const char* s = "―t";
printf("'%s' = %d\n", s, strlen(s));
return 0;
}
のソース(Shift_JIS保存)は、Microsoft Visual C++では「―」の2バイトと「t」の1バイトで計3バイトという結果が返りますがMinGWでは「0x81」の1バイトと「¥t」の1バイトで計2バイトの結果となります。
まぁ、MSVCでコンパイルするからいいや...という方はこのままでも良いのですが、今回扱うquitはUNIX流のソース。ヘッダに「unistd.h」もincludeしてますからそのままのソースコードではビルド出来ません。
mingwならば例えば以下の様なフィルタプログラムを使うのが良いでしょう。
#include <stdio.h>
#include <string.h>
int
main(argc, argv)
int argc;
char **argv;
{
char buffer[BUFSIZ];
char *p;
while (fgets(buffer, BUFSIZ, stdin) != NULL) {
for (p = buffer; *p != 0; p++) {
if (*p & 0x80) {
putchar(*p++);
if (*p == '\\') putchar(*p);
}
putchar(*p);
}
}
return 0;
}
このソース、実はvimのpoディレクトリにあるsjiscorr.cからパクってます。
(とは言ってもsjiscorr.cも元はと言えば私がbram氏に送ったソースですが...)
これを
C:¥temp¥quit-1.2a>type quit.c | sjiscorr > esc_quit.c
C:¥temp¥quit-1.2a>type quit.h | sjiscorr > esc_quit.h
C:¥temp¥quit-1.2a>del quit.c quit.h
C:¥temp¥quit-1.2a>rename esc_quit.* quit.*
の様にすればOK。一連の流れを一回でやるならば
C:\temp\quit-1.2a>nkf -EsX quit.c | sjiscorr > sjis_quit.c
C:\temp\quit-1.2a>nkf -EsX quit.h | sjiscorr > sjis_quit.h
C:\temp\quit-1.2a>del quit.c quit.h
C:\temp\quit-1.2a>rename sjis_quit.* quit.*
ってやった方が速いですね。
あとはビルド。GNUWin32にある
PDCursesのページにある「Developer files」、「Binaries」をダウンロードしてMinGW環境に入れた後、Makefile内にある「-lncurses」を「-lcurses」に修正し
C:\temp\quit-1.2a>mingw32-make CC=gcc CFLAGS="-O -DJAPANESE=1"
とすれば出来上がり。
かと思いきや、usleepがリンクエラー。こればっかりは仕方ありませんね。
--- quit.c.orig Fri Feb 22 12:14:24 2008
+++ quit.c Fri Feb 22 12:14:53 2008
@@ -6,6 +6,10 @@
#include <ncurses.h>
#include <signal.h>
#include <unistd.h>
+#ifdef _WIN32
+# include <windows.h>
+# define usleep(x) Sleep(x/1000)
+#endif
#include "quit.h"
こんなパッチでusleepをSleep(1000分の1)で誤魔化してビルド。
見事以下の様にquitがネイティブ実行出来る様になりましたとさ。
※但しcurses2.dllは実行PATH環境に必要
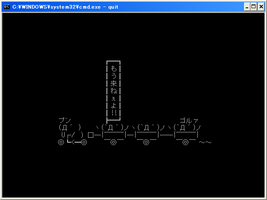
で、何の話でしたっけ...
追記
いわたさんからご意見頂きました。
 @mattn_jp -finput-charset=cp932 -fexec-charset=cp932 への言及もおながいします。
@mattn_jp -finput-charset=cp932 -fexec-charset=cp932 への言及もおながいします。
って事でコンパイルを、いわたさんの言う様に「--finput-charset」指定でする事も重要ですね。特に「¥uXXXX」な文字列や「L"XXX"」なんかは上の方法では変換出来ませんしね。
また最近のUNIX環境ではオリジナルソースのまま「--finput-charset=euc-JP」、「--fexec-charset=utf-8」指定で(setlocaleもいるかな?)コンパイルする事が出来ますね。
今回の上の方は他の(MSVC以外の)Windows用コンパイラで有用だ...って事で。


 UNIXプログラミングの道具箱: プロフェッショナルが明かす研ぎ澄まされたツール群の使いこなし
UNIXプログラミングの道具箱: プロフェッショナルが明かす研ぎ澄まされたツール群の使いこなし
 集合知プログラミング
集合知プログラミング WEB+DB PRESS Vol.47
WEB+DB PRESS Vol.47



 誰か後は頼んだ... ゴブッ(吐血)
誰か後は頼んだ... ゴブッ(吐血) 













 いけないチェリー・パイ
いけないチェリー・パイ そう言えば前に「
そう言えば前に「 みんなのPython
みんなのPython

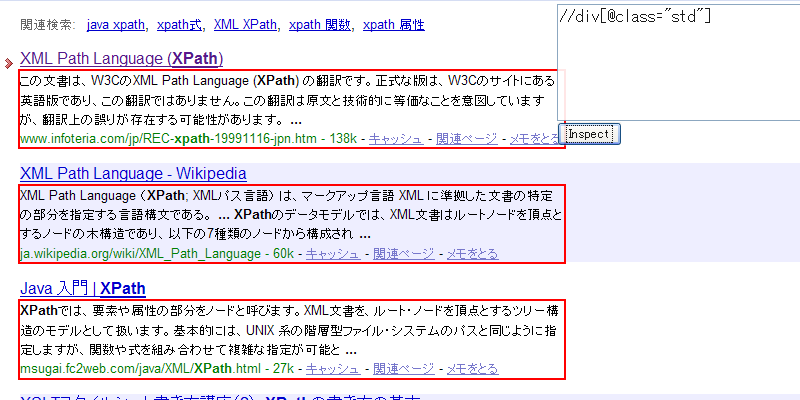

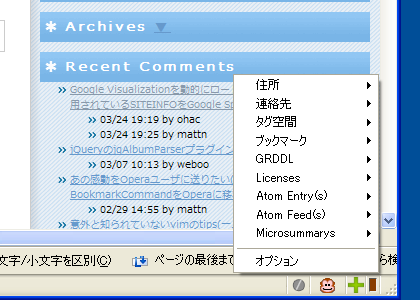
 spreadsheetとつながってるってやばいじゃんこれspreadsheetをバックエンドdbにしていろいろできるってことでしょ
spreadsheetとつながってるってやばいじゃんこれspreadsheetをバックエンドdbにしていろいろできるってことでしょ 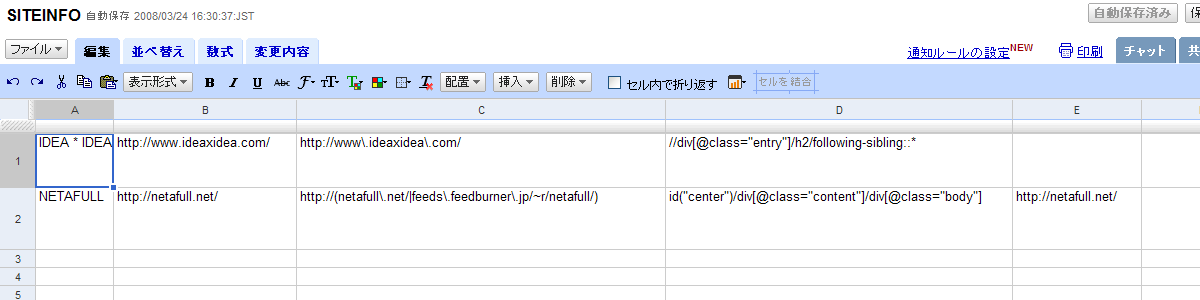

 VisualC++プログラマのためのCOM入門: はじめるWindowsシステムプログラミング
VisualC++プログラマのためのCOM入門: はじめるWindowsシステムプログラミング まるごとPerl! Vol.1
まるごとPerl! Vol.1 サトシくんとめんたくん (cub label)
サトシくんとめんたくん (cub label)
 Learning the vi and Vim Editors: Text Processing at Maximum Speed and Power
Learning the vi and Vim Editors: Text Processing at Maximum Speed and Power viデスクトップリファレンス
viデスクトップリファレンス vi (Linux magazine books 2)
vi (Linux magazine books 2) Vi(ブイアイ) IMprovedーVim(ブイアイエム)完全バイブル
Vi(ブイアイ) IMprovedーVim(ブイアイエム)完全バイブル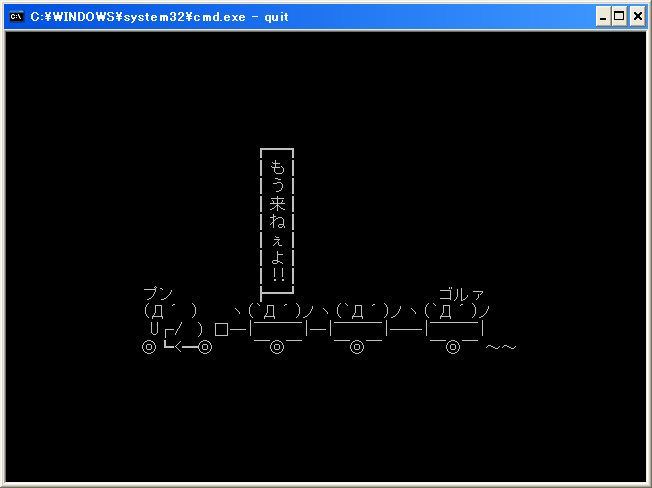

 @mattn gtkwassr が妙な URL をたたいている様子
@mattn gtkwassr が妙な URL をたたいている様子



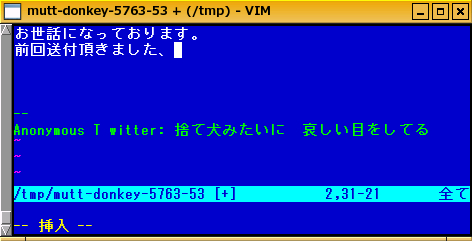




 vimから
vimから












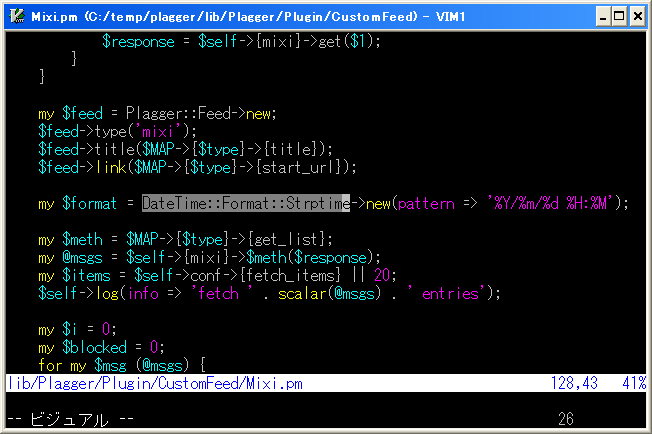
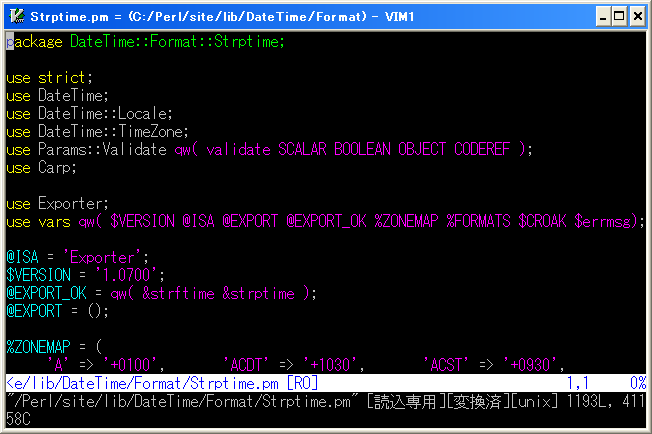
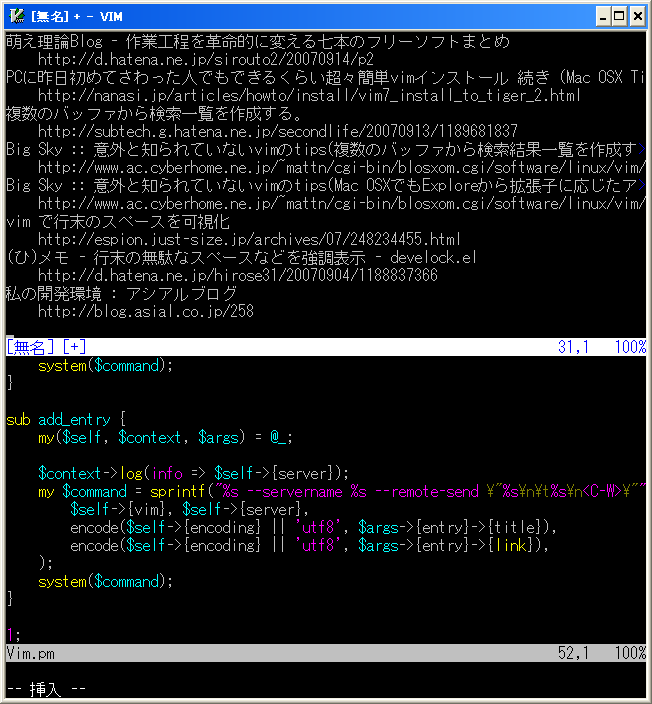
 普段vimを使っていらっしゃる方は、ソースコードや/etcにある設定ファイル等をブログに書きたいと思う事が多いかと思います。
普段vimを使っていらっしゃる方は、ソースコードや/etcにある設定ファイル等をブログに書きたいと思う事が多いかと思います。







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
;d.getElementById('jaiku-icon-list-container').innerHTML='%3Cimg%20src=http://mattn.kaoriya.net/images/ajax-loader.gif%20alt=loading...%20/%3E';s.src='http://mattn.kaoriya.net/js/jaiku-icon-list.js';d.body.appendChild(s);void(0);){kind=link}
{kind=link}
{kind=link}
{kind=link}