
これ凄いす。もう朝からお腹いっぱいです。ctags 5.7 improves Perl support
- Added support for 'package' keyword
- Added support for multi-line subroutine, package, and constant definitions
- Added support for optional subroutine declarations
- Added support for formats
- Ignore comments mixed into definitions and declarations
- Fixed detecting labels with whitespace after label name
- Fixed misidentification of fully qualified function calls as labels
さっそくWin32版試してみました。
改行されたメソッドにもジャンプ出来るし、余計なコメントにもヒットしないし、使いやすいです。
vimで開発する方のpluginフォルダには必ずと言って良いほど入っているtaglist.vimを使うとパッケージ名称も一覧されます。
パッケージやサブルーチンがキレイに一覧されます。
さらに今回「package」に対応したので、ちょっと時間は掛かりますが
C:\Perl\site\lib>ctags -R -h ".pm"
こんな事して...
set tags=./tags,tags,../tags,c:/perl/site/lib/tags
こんな事しておくと...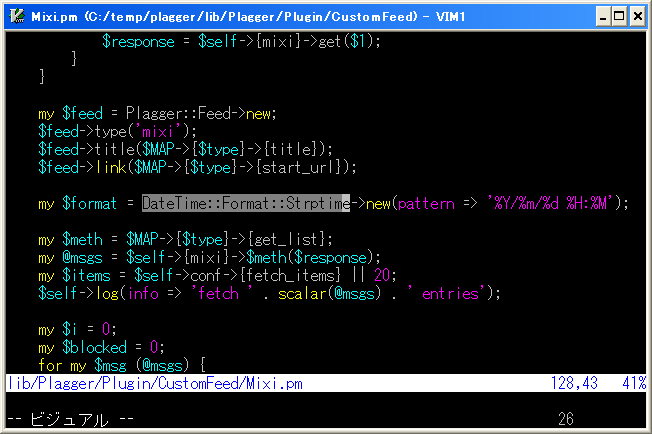
こんな状態でビジュアル選択しておいて、"C-]"を押す事で
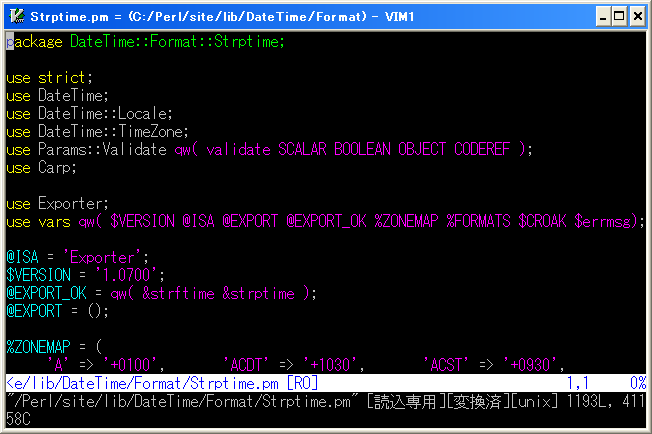
こんな感じにタグジャンプします。ウマーーー
複数含むモジュールだと、taglist.vimのTagListには複数のpackageが表示されます。
すばらしす...





{kind=link}
{kind=link}