「XML::Atom::Server::Lite」は「XML::Atom::Server」と構造をほぼ同じにしてあり、中で使用しているXML::Atomを自前のXSを使わないクラスで置き換えてしまおうというモジュールです。
LibXMLが使えないサーバには、もしかしたら有用かもしれません。サーバ用途だけならばLWPも使いませんし、簡単に低コストでAtom::Serverが実現出来ると思います。
「Digest::SHA」も「Digest::SHA::PurePerl」で置き換えています。
今日はこの「XML::Atom::Server::Lite」を使ってblosxomのAtom::Serverを作ってみました。
ソースは以下の通り。
#!/usr/bin/perl
package Blosxom::AtomPP;
use strict;
use base qw( XML::Atom::Server::Lite );
use File::Find;
use File::stat;
if (-e "/path/to/blosxom/config/file/config.cgi") {
package blosxom;
require '/path/to/blosxom/config/file/config.cgi';
}
my %Passwords = (
yourname => 'yourpassword',
);
my $postsWanted = 10;
sub password_for_user {
my $server = shift;
my($username) = @_;
$Passwords{$username};
}
sub getFilenameFromPostId {
my $postid = shift @_;
unless ( $postid =~ /$blosxom::datadir/ ) {
if ( $postid =~ m!^/! ) {
#Post ID now has a preceeding /
$postid = $blosxom::datadir . $postid;
} else {
$postid = "$blosxom::datadir/$postid";
}
}
return $postid;
}
sub getRandomFilename {
my $time = time;
$time .= int( rand(10) );
$time .= int( rand(10) );
return $time;
}
sub decode_html {
my $str = shift @_;
$str =~ s/&#([0-9]+);/chr($1)/ge;
$str =~ s/&#[xX]([0-9A-Fa-f]+);/chr(hex $1)/ge;
$str =~ s!\x0D|\x0A!<br />\n!g;
$str =~ s/\>/>/g;
$str =~ s/\</</g;
$str =~ s/\"/"/g;
$str =~ s/\&/\&/g;
return $str;
}
sub getPost {
my $filename = shift @_;
my $start = shift @_ || $blosxom::datadir;
my $extension = shift @_ || $blosxom::file_extension;
if ( -e $filename ) {
open POST, "$filename";
my @post = <POST>;
close POST;
my %struct;
$struct{'postid'} = $filename;
$struct{'dateCreated'} = File::stat::stat($filename)->mtime;
my $title = shift @post;
$title =~ s!\x0D|\x0A!!g;
$struct{'title'} = $title;
foreach (@post) {
my $line = $_;
if ( !$struct{'subject'} && $line =~ /^meta-tags: (.*)$/ ) {
$line = $1;
$line =~ s!\x0D|\x0A!!g;
my @subjects = split(/\s*,\s*/, $line);
$struct{'subject'} = \@subjects;
} else {
$struct{'description'} .= $line;
}
}
my @cats;
$filename =~ s/$start(\/.*)\/.*$extension$/$1/ or $filename = "/";
push @cats, $filename;
$struct{'categories'} = \@cats;
return \%struct;
}
else {
return 0;
}
}
sub newPost {
my $struct = shift @_;
my $start = shift @_ || $blosxom::datadir;
my $extension = shift @_ || $blosxom::file_extension;
my $filename;
if ( defined( $struct->{'postid'} ) ) {
$filename = getFilenameFromPostId( $struct->{'postid'} );
}
else {
$filename = lc( $struct->{'title'} );
$filename =~ s/\W+/_/g;
$filename =~ s/_+$//;
$filename = getRandomFilename() unless $filename =~ m/[a-z]/;
if ( $struct->{'categories'} ) {
$filename =
"$start/$struct->{'categories'}[0]/$filename.$extension";
}
else {
$filename = "$start/$filename.$extension";
}
}
chomp $struct->{'title'};
chomp $struct->{'description'};
unless ( -e $filename ) {
open POST, ">$filename.old" or die "Can't Open File $filename: $!";
print POST decode_html($struct->{'title'})."\n";
print POST decode_html($struct->{'description'})."\n";
close POST;
my $files = chmod 0664, $filename;
}
return $filename;
}
sub getEntry {
my $filename = shift;
my $post = getPost( $filename );
return unless $post;
my $entry = XML::Atom::Server::Lite::Entry->new;
my $extension = $blosxom::file_extension;
$entry->title($post->{title});
my $url = $blosxom::url.$post->{'postid'};
$url =~ s/$extension$/htm/;
$entry->link({
type=>'text/html',
rel=>'alternate',
href=>$url,
});
$entry->content({
mode=>'xml',
type=>'xhtml',
body=>$post->{description},
});
for my $cat (@{$post->{categories}}) {
$entry->category({
term=>$cat,
label=>$cat,
});
}
$entry->subject(@{$post->{subject}});
return $entry;
}
sub handle_request {
my $server = shift;
my $method = $server->request_method;
$server->authenticate or return;
if ($method eq 'POST') {
return $server->new_post;
}
$server->response_code(200);
$server->response_content_type('application/x.atom+xml');
my $start = $blosxom::datadir;
my $extension = $blosxom::file_extension;
my $url = $server->path_info;
if ($url =~ /$blosxom::file_extension$/) {
my $entry = getEntry( "$start/$url.old" );
return $entry->as_xml;
} else {
my %posts;
File::Find::find(
sub {
$File::Find::name =~ /$extension$/
? $posts{$File::Find::name} =
File::stat::stat($File::Find::name)->mtime
: 0;
},
$start
);
my @postList = sort { $posts{$b} <=> $posts{$a} } keys %posts;
if ( $#postList > $postsWanted ) {
@postList = @postList[ 0 .. ( $postsWanted - 1 ) ];
}
my $feed = XML::Atom::Server::Lite::Feed->new;
$feed->title($blosxom::blog_title);
$feed->link({
rel => 'self',
type => 'application/atom+xml',
title => $blosxom::blog_title,
href => $server->uri,
});
$feed->link({
rel => 'alternate',
type => 'text/html',
title => $blosxom::blog_title,
href => $server->uri,
});
$feed->link({
rel => 'service.post',
type => 'application/x.atom+xml',
title => $blosxom::blog_title,
href => $server->uri,
});
for my $filename (@postList) {
my $entry = getEntry( $filename );
$feed->add_entry( $entry ) if $entry;
}
return $feed->as_xml;
}
}
my %esc = (
"\a" => "\\a",
"\b" => "\\b",
"\t" => "\\t",
"\n" => "\\n",
"\f" => "\\f",
"\r" => "\\r",
"\e" => "\\e",
);
sub qquote {
local($_) = shift;
s/([\\\"\@\$])/\\$1/g;
my $bytes; { use bytes; $bytes = length }
s/([^\x00-\x7f])/'\x{'.sprintf("%x",ord($1)).'}'/ge if $bytes > length;
return qq("$_") unless
/[^ !"\#\$%&'()*+,\-.\/0-9:;<=>?\@A-Z[\\\]^_`a-z{|}~]/; # fast exit
my $high = shift || "";
s/([\a\b\t\n\f\r\e])/$esc{$1}/g;
if (ord('^')==94) { # ascii
# no need for 3 digits in escape for these
s/([\0-\037])(?!\d)/'\\'.sprintf('%o',ord($1))/eg;
s/([\0-\037\177])/'\\'.sprintf('%03o',ord($1))/eg;
# all but last branch below not supported --BEHAVIOR SUBJECT TO CHANGE--
if ($high eq "iso8859") {
s/([\200-\240])/'\\'.sprintf('%o',ord($1))/eg;
} elsif ($high eq "utf8") {
# use utf8;
# $str =~ s/([^\040-\176])/sprintf "\\x{%04x}", ord($1)/ge;
} elsif ($high eq "8bit") {
# leave it as it is
} else {
s/([\200-\377])/'\\'.sprintf('%03o',ord($1))/eg;
s/([^\040-\176])/sprintf "\\x{%04x}", ord($1)/ge;
}
}
else { # ebcdic
s{([^ !"\#\$%&'()*+,\-.\/0-9:;<=>?\@A-Z[\\\]^_`a-z{|}~])(?!\d)}
{my $v = ord($1); '\\'.sprintf(($v <= 037 ? '%o' : '%03o'), $v)}eg;
s{([^ !"\#\$%&'()*+,\-.\/0-9:;<=>?\@A-Z[\\\]^_`a-z{|}~])}
{'\\'.sprintf('%03o',ord($1))}eg;
}
return qq("$_");
}
sub get_content_node {
my $tree = shift;
if ($tree->{children} && (@{$tree->{children}} eq 1)
&& $tree->{children}->[0]->{name} eq 'content') {
$tree = $tree->{children}->[0];
for my $item (@{$tree->{children}}) {
if ($item->{name} eq 'div' && $item->{attributes}
&& $item->{attributes}->{xmlns} =~ 'http://www.w3.org/1999/xhtml') {
$tree = $item;
for my $nobr (@{$tree->{children}}) {
return $nobr if $nobr->{name} ne 'br' && $nobr->{type} eq 'tag';
}
last;
}
}
}
$tree;
}
sub to_xml {
my $tree = shift;
my $xml;
if ($tree->{name}) {
$xml .= "<".$tree->{name};
for my $attr (keys %{$tree->{attributes}}) {
$xml .= " $attr=".qquote($tree->{attributes}->{$attr});
}
} elsif ($tree->{content}) {
$xml .= $tree->{content};
}
if ($tree->{children}) {
$xml .= ">" if $tree->{name};
foreach my $item (@{$tree->{children}}) {
$xml .= to_xml($item);
}
$xml .= "</".$tree->{name}.">" if $tree->{name};
} elsif ($tree->{name}) {
$xml .= "/>";
}
$xml;
}
sub new_post {
my $server = shift;
my $entry = $server->atom_body or return;
my $struct = {};
my $url = $server->path_info || $entry->link;
$url =~ s/htm$/$blosxom::file_extension/;
$struct->{postid} = $url;
$struct->{title} = $entry->title;
my $tree_parser = XML::Parser::Lite::Tree::instance();
my $tree = $tree_parser->parse( $entry->content->body );
my $data = to_xml(get_content_node($tree));
$struct->{description} = $data;
$struct->{categories} = $entry->{category};
my $filename = newPost( $struct );
my $created = getEntry( $filename );
$server->response_code(201);
$server->response_content_type('application/x.atom+xml');
$server->response_header(Location => $server->uri.$struct->{postid});
return $created;
}
package main;
my $server = Blosxom::AtomPP->new;
$server->run;
厳密な「service.post」や「alternate」ではありませんが「XML::Atom::Server::Lite」の検証としてはこの程度で十分かなと思ってます。ポストも出来ます(認証はWSSE)。Zoundry Ravenというブログツールでは動作を確認しました。
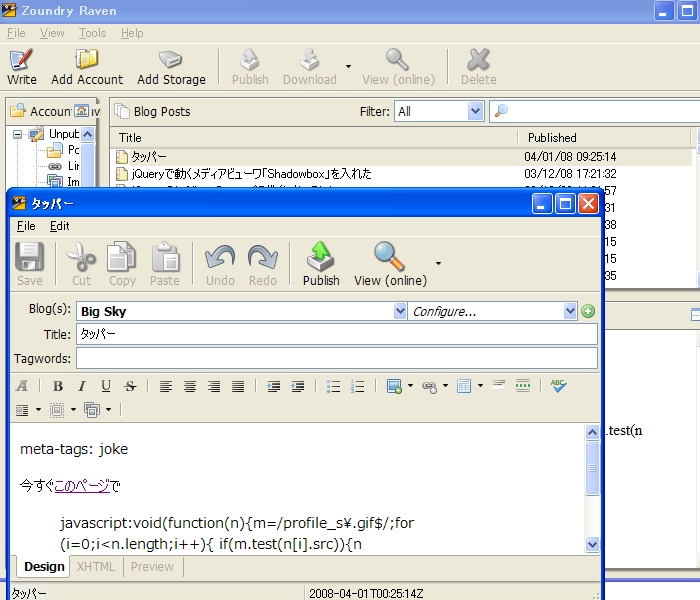
おそらくですが
- 「XML::Atom::Server::Lite」を「XML::Atom::Server」
- 「XML::Atom::Server::Lite::Feed」を「XML::Atom::Feed」に
- 「XML::Atom::Server::Lite::Entry」を「XML::Atom::Entry」に
なお、「XML::Atom::Server::Lite」はSOAPには対応していません。馬力のある方は適当に弄って下さい。
これでblosxomにXMLRPCとAtomのインタフェースが揃った事になるのかな?