
tl;dr: 可能な限り速くvim(人類史上、最良と知られているテキストエディタ)を習得したい。その方法を提案する。生き残るには最小を学ぶ事から始め、その後徐々にトリックを混ぜて行く。
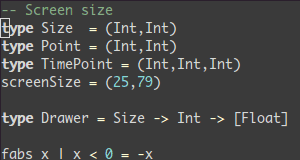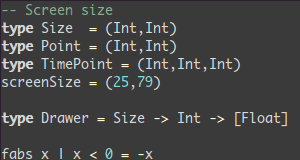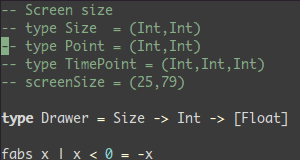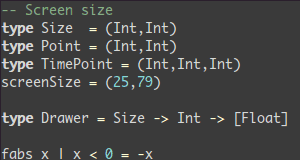
Vim 60億ドルのテキストエディタ
優れいて、強く、そして速い
vimを学ぶ事、それはあなたあなたが学ぶ最後のテキストエディタになるでしょう。私が知る限りより優れたテキストエディタはない。学ぶのは難しいが、使うと素晴らしい。
4つのステップで学ぶ事をお勧めする:
- 生き残る
- 心地よさを感じとる
- より良さ、強さ、速さを感じとる
- vimの強大な力を使う
この道のりの終端で、君はvimスーパースターになっているだろう。
しかし始める前に警告しておく。vimの学習は最初は苦痛となる。時間がかかり、沢山の楽器を演奏する様なものでもある。
3日程度で他のエディタよりもvimが効率的に使える様になるなんて事は期待しないで下さい。
現実的に、3日間どころか2週間は確実にかかります。
レベル1 – 生き残る
- vimをインストールし
- vimを起動する
- 何もするな!読め
通常のエディタでは、キーボードをタイプするだけで、何かを書いて画面で読む事が出来る。
ここではそうじゃない。
VimはNormalモードだ。
Insertモードになろう。
iの文字をタイプしよう。
ちょっとだけいい感じになるはずだ。
一般的なメモ帳みたいに文字をタイプ出切る。
Normalモードに戻るにはESCキーをタップするんだ。
InsertモードとNormalモードを切り替える方法を学んだ。
そして今、君が生き残る為にあるNormalモードのコマンドリストはこれだ:
i → Insertモード。ESCをタイプしてNormalモードに戻る。x → カーソル上の文字を消す。:wq → 保存して終了(:w保存, :q終了)。dd → 現在の行を削除(そしてコピー)p → ペースト
忠告:
hjkl (特に必須ではないが推奨する) → 基本的なカーソル移動 (←↓↑→). ヒント: jは下向き矢印の様に見えるよね。:help <コマンド> → <コマンド>のヘルプを表示する。何もなしで:helpとしても使い始める事が出切る。
たった5つのコマンドだ。はじめはとても少ない。
これらのコマンドが自然に使い始められる(どっぷり一日を費やすかもしれない)様になれば、レベル2に行くべきだろう。
でもその前に、ちょっとだけNormalモードについて言っておく。
一般的なエディタでは通常、コピーするのにCtrlキーを使う(Ctrl-c)。
実際には、Ctrlをタイプした時、それはキーの意味を変えるビットの様な物になる。
vimのNormal modeとは、このCtrlキーがずっと押しっぱなしになっている様な物だ。
注釈に関してお断り:
- 私は
Ctrl-λと書く代わりに<C-λ>と書いていく。
:によるコマンドは<enter>で終らなければならない。例えば、:qと書かれている場合それは:q<enter>を意味する。
レベル2 – 心地よさを感じ取る
あなたは生き残るために必要なコマンドを知っている。さらにいくつかのコマンドを学習しよう。
これを提案する:
-
Insertモードのバリエーション:
a → カーソルの後に挿入するo → 現在行の後の新しい行で挿入するO → 現在行の前の新しい行で挿入するcw → カーソル位置から単語の最後までを書き換える
-
基本的な移動
0 → 行の先頭に移動^ → その行の空白でない最初の文字へ移動$ → 行の末尾に移動g_ → その行の空白でない最後の文字へ移動/pattern → patternを検索
-
コピー/
P → 前にペースト。pはカーソル位置の後にペーストと覚えよう。yy → 現在の行をコピー。簡単に言えばddPと同じだ。
-
アンドゥ/リドゥ
-
読み込み/保存/終了/ファイル(バッファ)の変更
:e <path/to/file> → 開く:w → 保存:saveas <path/to/file> → <path/to/file>に保存ZZ or :wq → 保存して終了:q! → 保存せずに終了。また非表示のバッファに変更があっても:qa!で終了:bn (関連: :bp) → 次の(関連: 前の)ファイル(バッファ)を表示
これらのコマンドのすべてを統合するために時間がかかる。
一度やってみると分かるが、他のエディタで出切る全てを行う事が出切るはずだ。
ここまでも若干厄介だろう。 しかし次のレベルに従うとその理由が分かる。
レベル3 – より良さ、強さ、速さ
ここまでの到達おめでとう!
面白いことを始められる。
レベル3では、古いviと互換性のあるコマンドについて話す。
より良さ
Vimが、ユーザの繰り返し動作についてどう役に立ち得るかを見て行こう:
. → (ドット) は最後のコマンドを繰り返し- N<コマンド> → はN回繰り返す。
幾らか例を示す。ファイルを開き、タイプしよう:
2dd → は2行削除3p → はそのテキストを3回ペースト100iです [ESC] → は“です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です です “を書く。. → つい先ほどの最後のコマンド、“です “を100個書くのを再度行う。3. → 3個“です ”を書く(300じゃないよ。なんて賢い)。
強さ
vimを使って効率的に移動する方法を知ることは非常に重要だ。このセクションを飛ばしてはならない。
- N
G → N行に移動
gg → 1Gのショートカット。ファイルの先頭に移動G → 最後の行に移動-
単語の移動:
w → 次の単語の先頭に移動しe → その単語の終わりに移動する。
デフォルトでは単語とは文字とアンダースコアで構成されている。
WORDは空白文字で区切られた文字のグループと呼ぶことにしよう。
WORDと見なしたい場合は、単に大文字のを使おう。
W → 次のWORDの先頭に移動しE → そのWORDの終わりに移動する。
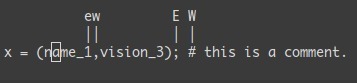
ここで、非常に効率的な移動について説明しよう:
% : (、{、[の対に移動。* (関連: #) : カーソル位置のある単語で次の(関連: 前の)物へ移動。
私を信じなさい。最後の3つのコマンドはゴールドだ。
速さ
viでの移動の重要性について覚えておきなさい。これには理由がある。
ほとんどのコマンドは、以下の一般形式を用いて使う事が出切る。
<開始位置><コマンド><終了位置>
例えば : 0y$ は以下を意味する
0 → この行の先頭に移動y → そこをヤンク$ → この行の末尾に向かって
yeの様な物でも行う事ができ、ここから単語の末尾までをヤンクする。
またy2/fooは2番目にある“foo”までをヤンクする。
だがy (ヤンク)だけではなく、d (削除)、v (ビジュアル選択)、gU (大文字)、gu (小文字)... 等でも同様だ。
レベル4 – Vimの強大な力
先に述べたコマンドを使用すれば、快適にvimを使えるはずだ。
しかしまだ、驚異的な機能ある。
これらの機能のいくつかが、私がvimを使い始める理由だった。
現在行での移動: 0 ^ $ f F t T , ;
0 → 行の先頭に移動^ → 行の最初の文字に移動$ → 行の最後の文字に移動fa → その行で次に見つかる文字aまで移動。, (関連: ;)は次に(関連: 前に)見つかるそれまで移動。t, → ,の前に移動。3fa → その行で3回目に見つかるaへ。F と T → f と t に似ているが後方だ。
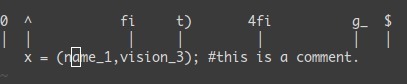
便利なtip: dt" → "までの全てを削除。
区域選択 <アクション>a<オブジェクト> もしくは <アクション>i<オブジェクト>
これらのコマンドは、ビジュアルモードでのオペレータの後でしか使う事が出来ない。
しかし非常に強力だ。主なパターンは以下の通り。
<アクション>a<オブジェクト> and <アクション>i<オブジェクト>
アクションは、アクションと成り得る如何なる場所にも位置出切る。例えばd (削除), y (ヤンク), v (ビジュアルモード選択)。
そしてオブジェクトは: w word、W WORD (拡張されたword)、s 文, p 段落。はたまた"、'、)、}、]といった自然な文字だ。
カーソルが(map (+) ("foo"))の最初のoにあると仮定する。
vi" → fooを選択va" → "foo"を選択vi) → "foo"を選択va) → ("foo")を選択v2i) → map (+) ("foo")を選択v2a) → (map (+) ("foo"))を選択

矩形ブロックを選択: <C-v>
矩形ブロックはコード上の多くの行をコメントするのにとても便利だ。
通常はこうだ: 0<C-v><C-d>I-- [ESC]
^ → 行の先頭に移動<C-v> → ブロック選択を開始<C-d> → 下へ移動(jjj や % …なんかでも移動出来る)I-- [ESC] → -- を書いてそれらの行をコメントアウト
Windows以外では、クリップボードが空でないなら<C-v>の代わりに<C-q>を使えるかもしれないね。
補完: <C-n> と <C-p>
Insertモードでは単語の先頭で<C-p>をタイプしてみよう。魔法だ...
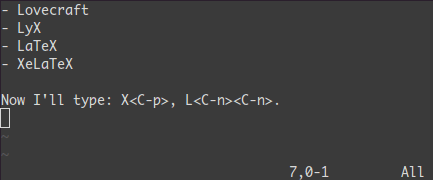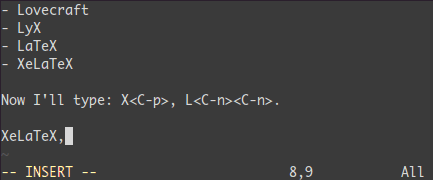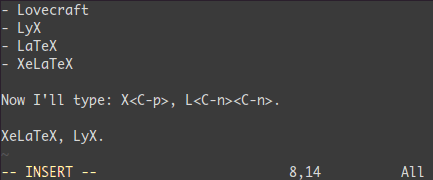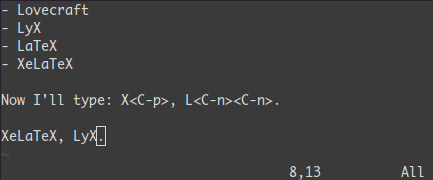
マクロ : qa 何か実行 q、@a、@@
qaでアクションをaregisterに記録。
そして@aはaレジスタに記録されたマクロを、あたかもそれを入力したかの様に再生。
@@は最後に実行したマクロを再生するショートカットだ。
例
数字の1だけ含んだ1行で、これをタイプしよう:
-
qaYp<C-a>q →
qa 記録を開始Yp 行を複製<C-a> 数字を増やすq 記録を止める
@a → 1の下に2が書かれる@@ → 2の下に3が書かれる- じゃあ、
100@@で103までの連番リストが作れるよね。

ビジュアル選択: v,V,<C-v>
<C-v>を使った例があった。そこで
v と
Vだ。
選択モードになると、次の操作が実行出切る:
J → 全ての行を結合< (関連: >) → 左へ(関連: 右へ)インデント= → オートインデント
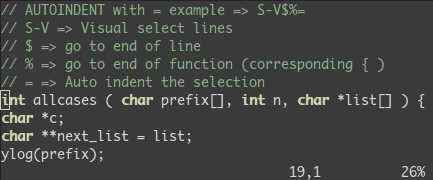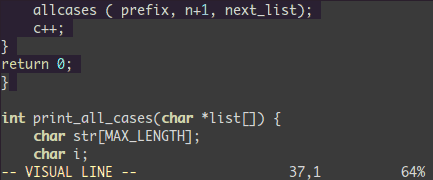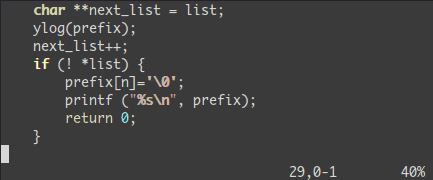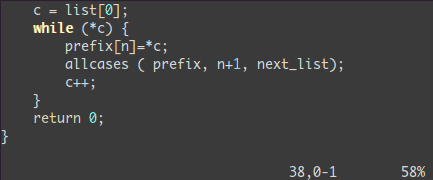
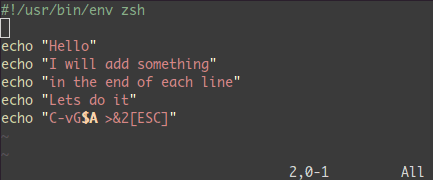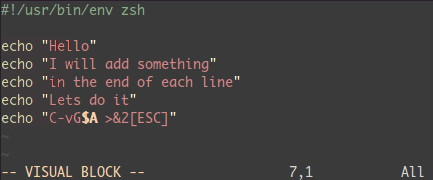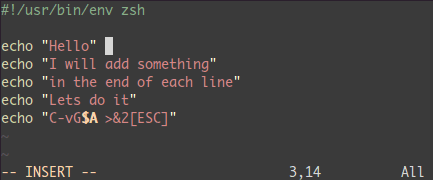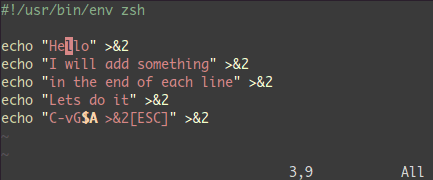
ビジュアル選択した全ての行の末尾に何かを追加しよう:
<C-v> - 目的の行に移動しよう(
jjj や <C-d> や /pattern や % …なんかで)
$ 行末に移動A テキストを書き込み、ESC
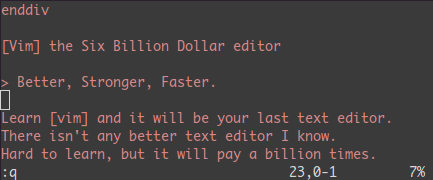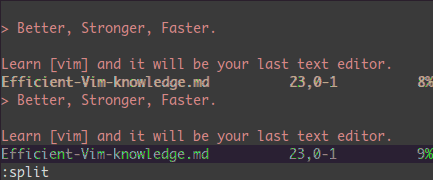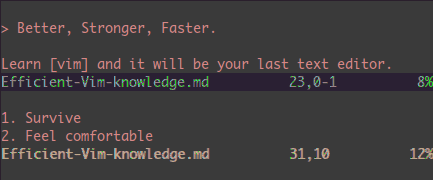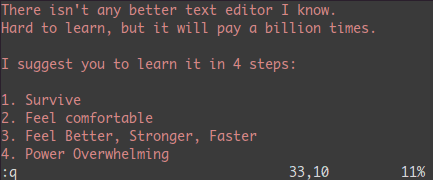
分割: :split と vsplit
主なコマンドは以下の通りですが、:help splitで調べるべきでしょう
:split → 分割(:vsplit は縦分割)ウィンドウを作る<C-w><dir> : hjklで示す←↓↑→の方向へ分割を変更する<C-w>_ (関連: <C-w>|) : 分割サイズを最大に(関連: vertical split)<C-w>+ (関連: <C-w>-) : 分割サイズを増やす(関連: shrink)
終わりに
これらは私が日々使用しているコマンドの90%だ。
私は君が一日あたり1つないしは2つ以上の新しいコマンドを学習しないように提案しておく。
2~3週間後には、君はvimのパワーを君自身の手で感じ始めるだろう。
Vimの学習は単なるの暗記よりも多くの訓練の方が必要となる。
幸いにもvimには幾つかの非常に有用なツールと優れたドキュメントが付属している。
最も基本的なコマンドに慣れるまではvimtutorを実行しよう。
また注意してこのページを読むべきだ: :help usr_02.txt
そして、!、折りたたみり、レジスタ、プラグインや、他の多くの機能について学ぶであろう。
vimの学習とは、ピアノを学ぶ様に素敵な事だ。




